本文介绍Docker底层资源隔离和限制的相关知识。Docker本质上是宿主机(Linux)上的进程,通过namespace实现资源隔离,通过cgroups实现资源限制,通过写时复用机制(copy-on-write)实现高效的文件操作。
Namespace资源隔离机制
namespace是Linux提供的资源隔离机制。只有在同一个namespace下的进程可以相互联系,但无法感受到外部进程的存在,营造出处于一个独立的系统环境中的错觉,从而实现了隔离。
Linux提供的操作namespace相关接口介绍如下:
clone()
clone()是fork()的一种实现方式。调用fork()函数时系统会创建新进程,为其分配资源,并把原来进程中的值复制到新进程中,可通过fpid区分新进程和父进程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
运行:
1
| |
输出:
I am parent. pid: 33390
I am child. pid: 33391
参数:
- child_func:程序主函数
- child_stack:栈空间
- flags:系统调用参数
setns()
setns()用于加入已存在的namespace
1
| |
参数
- fd:要加入namespace的文件描述符(指向/proc/[pid]/ns目录)。
- nstype:要加入namespace的类型,用于检查,0表示不检查。
unshare()
unshare()在原进程上进行namespace隔离。
1
| |
unshare()不启动新进程,但是跳出了原来的namespace。
Namespace 6项隔离介绍
namespace提供了以下6项隔离:
| namespace | 系统调用参数 | 隔离内容 |
|---|---|---|
| UTS | CLONE_NEWUTS | 主机和域名 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
| User | CLONE_NEWUSER | 用户和用户组 |
Unix Time-sharing System(UTS) namespace
分时系统(Time-sharing System)中一台主机连接了若干个终端,每个终端有一个用户在使用。
用户交互式地向系统提出命令请求,系统接受每个用户的命令,采用时间片轮转方式处理服务请求,并通过交互方式在终端上向用户显示结果。用户根据上步结果发出下道命令。
分时操作系统将CPU的时间划分成若干个片段,称为时间片。操作系统以时间片为单位,轮流为每个终端用户服务。每个用户轮流使用一个时间片而使每个用户并不感到有别的用户存在。
UTS(Unix Time-sharing System) namespace提供了主机名和域名的隔离,使每个Docker容器可以拥有独立的主机名和域名,在网络上可以视为独立的节点。
Unix Interprocess Communication(IPC) namespace
Linux进程间通信由System V IPC,基于Socket的IPC和POSIX IPC发展而来,主要的通信手段有:
- 管道(Pipe)
- 无名管道
-只能用于具有亲缘关系的进程之间的通信(父子进程或者兄弟进程之间)
- 半双工的通信模式,具有固定的读端和写端
- 是一种特殊的文件,不属于其他任何文件系统并且只存在于内存中
- 有名管道(FIFO)
- 使互不相关的两个进程间实现彼此通信
- 可以通过路径名来指出,并且在文件系统中是可见的。在建立了管道之后,两个进程就可以把它当做普通文件一样进行读写操作
- 先进先出规则
- 无名管道
-只能用于具有亲缘关系的进程之间的通信(父子进程或者兄弟进程之间)
- 信号(Signal)
- 用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身
- 消息队列(Message Queue)
- 有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。
- 克服了信号承载信息量少,管道只能承载无格式字节流(要求管道的读出方和写入方必须事先约定好数据的格式,比如多少字节算作一个消息等)以及缓冲区大小受限等缺点。
- 共享内存
- 使得多个进程可以访问同一块内存空间。
- 信号量(semaphore)
- 主要用于进程间以及同一进程不同线程之间的同步。
- 套接字(Socket)
- 可用于不同机器之间的进程间通信,必须包含
- 地址,由 ip 与 端口组成,像192.168.0.1:80。
- 协议,socket 所用的传输协议 TCP、UDP、raw IP。
- 可用于不同机器之间的进程间通信,必须包含
IPC资源包括信号量、消息队列和共享内存。
IPC namespace中包含系统IPC标识符以及实现POSIX消息队列的文件系统。
同一个IPC namespace下的进程彼此可见,不同IPC namespace下的进程互相不可见。
通过IPC namespace可以实现容器与宿主机、容器与容器之间的IPC隔离。
Process identifier(PID) namespace
PID是大多数操作系统的内核用于唯一标识进程的一个数值。
这一数值可以作为许多函数调用的参数,以使调整进程优先级、杀死进程之类的进程控制行为成为可能。
PID为1的进程是init,作为所有进程的父进程,不会处理来自其他进程的信号(信号屏蔽),并维护一张进程表,当有子进程变成孤儿时会回收其资源并结束进程。
PID namespace隔离对进程PID重新编号,两个不同namespace下的进程没有关系,因此PID也可以相同。内核为所有的PID namespace维护了一个树状结构。
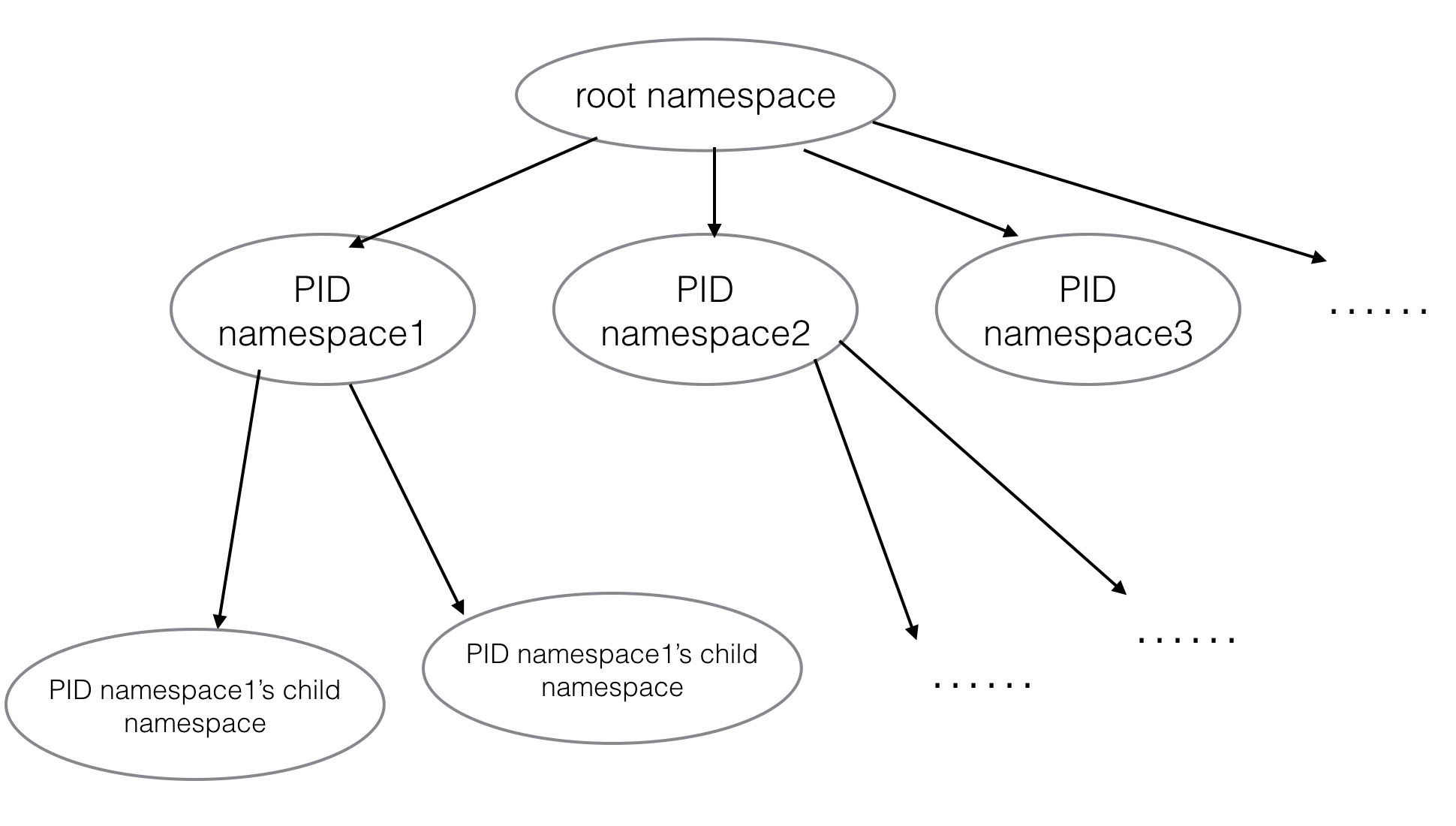
其中:
- 每个PID namespace中的第一个进程拥有特权。
- 一个namespace中的进程不能影响父节点或兄弟节点namespace中的进程。
- root namespace中可以看到所有的进程,包括所有后代节点中的namespace。
- 在外部可以通过监控Docker daemon所在的PID namespace中的所有进程和子进程来实现对Docker中运行的程序的监控。
Mount namespace
mount namespace 通过隔离文件系统挂载点隔离文件系统,它是第一个Linux namespace,标识位为CLONE_NEWNS。隔离之后不同的mount namespace中的文件结构互不影响。
可以通过/proc/[pid]/mounts查看所有挂载在当前namespace中的文件系统。进程创建mount namespace时把当前文件结构复制给新的namespace。
挂载传播(mount propagation)定义了挂载对象之间的关系,解决了文件结构复制过程中子节点namespace影响父节点namespace文件系统的问题。
- 共享关系(share relationship):存在挂载关系的两个挂载对象中的事件会双向传播
- 从属关系(slave relationship):挂载对象中的事件只能按指向从属对象的方向传播(共享挂载—>从属挂载)
Network namespace
network namespace提供了关于网络资源的隔离,包括网络设备、IPv4和IPv6协议栈、IP路由表、防火墙、/proc/net目录、/sys/class/net目录、套接字(socket)等。
注意:
- 一个物理的网络设备最多存在于一个network namespace中
- 可以通过veth pair在不同的network namespace中创建通道进行通信。
- 一般情况下,物理网络设备都分配在最初的root namespace中。
User namespace
user namespace主要隔离了安全相关的标识符和属性(用户ID、用户组ID、root目录、key(密钥)、特殊权限)。
因此用clone()创建的新进程在新的user namespace中可以拥有不同的用户和用户组,在新进程创建的容器中,它是超级用户,但在容器之外只是普通用户。
Linux中,特权用户的user ID是0,user ID非0的进程启动user namespace后user ID可以变为0
cgroups资源限制机制
cgroups是Linux内核提供的一种机制。
这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,限制了被namespace隔离起来的资源,并为资源设置权重、计算使用量(CPU, Memory, IO等)、操控任务启停等。
从而为系统资源管理提供了一个统一的框架。
cgroup功能
cgroup提供的主要功能如下:
- 资源限制:限制任务使用的资源总额,并在超过这个配额时发出提示
- 优先级分配:分配CPU时间片数量及磁盘IO带宽大小、控制任务运行的优先级
- 资源统计:统计系统资源使用量,如CPU使用时长、内存用量等
- 任务控制:对任务执行挂起、恢复等操作
cgroup子系统
cgroups的资源控制系统,每种子系统独立地控制一种资源。
- cpu:使用调度程序控制任务对CPU的使用。
- cpuacct(CPU Accounting):自动生成cgroup中任务对CPU资源使用情况的报告。
- cpuset:为cgroup中的任务分配独立的CPU(多处理器系统时)和内存。
- devices:开启或关闭cgroup中任务对设备的访问
- freezer:挂起或恢复cgroup中的任务
- memory:设定cgroup中任务对内存使用量的限定,并生成这些任务对内存资源使用情况的报告
- perf(Linux CPU性能探测器)_event:使cgroup中的任务可以进行统一的性能测试
- net_cls(Docker未使用):通过等级识别符标记网络数据包,从而允许Linux流量监控程序(Traffic Controller)识别从具体cgroup中生成的数据包
参考资料
本文参考如下博文整理:
namespace的详细介绍可以参考: